The most popular advice on performance benchmarking is also the least useful once a brand starts expanding. Compare channels. Compare regions. Compare this month to last month. Then decide what's “working”.
That logic breaks down quickly in practice.
One pattern we continue seeing is that established brands misread weak early signals in a new market as proof of poor product-market fit, when the actual problem is that they're benchmarking unlike-for-unlike. An Australian brand with strong retail recognition, predictable replenishment, and a mature fulfilment setup at home can look underpowered in the UK, Canada, or the US for reasons that have very little to do with the product itself. The new-market ecosystem is younger, less trusted, less localised, and often operationally less settled.
Performance benchmarking only helps when it explains context, not when it flattens it.
For founders and commercial leaders, that matters because bad comparison logic creates expensive decisions. Teams cut localisation too early. They underinvest in stock depth. They mistake marketplace immaturity for category weakness. They retreat from regions that were never given a fair commercial reading in the first place.
Why Most Performance Benchmarking Fails During Expansion
The failure usually starts with a simple comparison that feels sensible.
An Australian consumer electronics brand launches into a new region. Sales velocity is lower than at home. Conversion is softer. Reviews build more slowly. The immediate conclusion is that the offer is weaker in that market.
Often, it isn't.
The comparison is flawed because the operating context is different. The domestic market may already have strong brand recall, cleaner authorised distribution, faster replenishment, and customers who understand the product category. The new market may have none of those advantages yet. Comparing the two as if they sit on the same baseline turns performance benchmarking into a distortion device.
Benchmark validity matters more than most teams realise
A recurring weakness in benchmarking practice is benchmark validity. Research on reliable benchmarking notes that it requires both a clearly defined contextual level and a universally relevant set of domains, and it also highlights that these levels have often been poorly defined in prior work. That becomes especially important when comparing channels or export markets with different assortment mixes and service models, including the unresolved question, “Which benchmark should we trust when our channel mix is changing?” as discussed in this research on contextualised benchmarking.
That question sits at the centre of international marketplace expansion.
If your Australian DTC business has one service promise, your UK marketplace business has another, and your wholesale-led US entry has a third, then a blunt KPI comparison tells you very little. It may show a difference. It won't explain whether that difference is healthy, temporary, structural, or dangerous.
Practical rule: A benchmark is only useful if the comparison group operates under roughly similar commercial conditions.
That's why many expansion teams overreact. They aren't reading performance. They're reading context noise.
The wrong comparison produces the wrong decision
Across multiple marketplace ecosystems, the most damaging benchmarking mistakes tend to look like this:
Home market versus launch market parity tests
Teams expect a newly entered region to behave like a mature domestic ecosystem.Channel averages used as strategic truth
Category averages hide differences in price architecture, fulfilment model, and localisation quality.Revenue-first comparisons
Top-line movement gets treated as proof of strength, even when the underlying operating model is unstable.
This is also where broader online selling strategy gets misunderstood. Brands think they're evaluating market demand when they're evaluating channel readiness, operational fit, and ecosystem maturity all at once.
Good performance benchmarking separates those variables. Weak benchmarking collapses them into one misleading story.
Benchmarking as a Navigational Tool Not a Scorecard
Most brands still treat benchmarking like an exam result. They want to know whether they're above average, below average, or catching up.
That mindset is too static for expansion.
When a brand enters a new region, the better use of performance benchmarking is navigational. It helps a team decide whether pricing is calibrated for the market, whether fulfilment is building trust or eroding it, whether localisation is reducing friction, and whether the channel structure matches the product's positioning. The benchmark is not there to flatter or punish. It's there to orient decisions.

What meaningful comparison actually requires
For performance benchmarking to mean anything, the comparison has to use quantitative KPIs with consistent definitions against a defined peer set. The more thorough approach is to normalise those KPIs for industry, geography, and business maturity so teams can identify true performance gaps rather than artefacts of misalignment, as outlined by APQC on benchmarking types and KPI comparison.
That point sounds technical, but commercially it's straightforward.
If one brand is benchmarking a marketplace launch against incumbents with local warehousing, native-language content, entrenched reviews, and stable reseller control, then “underperformance” may reflect a different stage of market establishment. The benchmark needs to account for maturity, not erase it.
The better question for operators
The wrong question is, “Are we beating the market average?”
The better questions are usually these:
| Question | What it reveals |
|---|---|
| Are our KPIs defined consistently across markets | Whether the comparison is valid at all |
| Are we comparing against brands with a similar operating model | Whether the benchmark is commercially fair |
| Is the market punishing our product, or our setup | Whether the issue is offer, execution, or structure |
| Are we improving in the areas that matter for this region | Whether investment is creating useful traction |
One issue we repeatedly observe is that top brands don't rely on a single benchmark view. They use several. One for commercial velocity. One for operational reliability. One for margin protection. One for localisation effectiveness. Together, those views form a navigation system.
A scorecard tells you where you rank. A navigation tool tells you where to adjust.
That difference matters most when visibility is poor. Early expansion often is. Customer response is still forming. Channel partners are still settling. Marketplace signals are mixed. In that environment, performance benchmarking should reduce uncertainty, not create false certainty.
A Framework for Meaningful Marketplace Comparison
The most useful benchmarking model for international expansion isn't channel-to-channel. It's ecosystem-aware.
That means evaluating performance through a set of connected pillars that explain how the market is functioning around the brand, not just what the topline says. A sales number without context can hide margin stress, poor localisation, weak fulfilment confidence, or fragmented channel control.
A good framework needs common language. Australia offers a strong public-sector precedent for that. The National Health Performance Framework, established under AHMAC in 2001, used three tiers, health outcomes, system performance, and determinants of health, to create a common language for comparing performance across jurisdictions and linking measurement to accountability and decision-making, as described in this overview of structured benchmarking in Australia. Commercial teams can learn from that discipline. Define the layers clearly, then benchmark them consistently.
Five pillars that make the comparison usable
Sales and commercial velocity
Teams often commence their efforts at this stage, only to cease progress prematurely.
Sales velocity matters, but on its own it's a blunt instrument. In a new market, commercial velocity should be read alongside order quality, repeat behaviour, pricing stability, and whether demand is broadening across the catalogue or clustering around a narrow set of SKUs.
A brand that sells quickly through one hero product but fails to widen adoption may have demand. It may also have an ecosystem that still doesn't understand the wider range.
Channel health and fragmentation
A recent marketplace review revealed how often brands confuse presence with control. They see listings, traffic, and resellers and assume the ecosystem is functioning.
Sometimes it isn't.
Channel health means checking whether sales are happening through the right seller structure, whether unauthorised listings are distorting price perception, and whether the catalogue looks coherent across the marketplace. Fragmentation often appears before financial damage becomes obvious.
Authorised seller alignment
Clean channel structure supports trust and pricing discipline.Catalogue coherence
Inconsistent titles, bundles, images, or variants often signal weak governance.Promotional integrity
Heavy discounting in one seller node can quietly damage the wider market.
Supply chain and fulfilment confidence
For physical product brands, fulfilment is part of market positioning.
Customers don't separate the product from the delivery promise. If availability is patchy, lead times are uncertain, or returns handling feels weak, the market often interprets that as brand unreliability rather than operational growing pains. This becomes even more visible during global product launch planning, where the commercial model and fulfilment structure need to support each other from day one.
Operational observation: In expansion, fulfilment is often the first hidden variable that distorts benchmark readings.
Product quality and localisation fit
This pillar is where many false positives get exposed.
Strong demand with rising returns, confused reviews, or repetitive customer complaints doesn't indicate traction. It indicates friction. The product may be good, but the way it is presented, explained, bundled, or supported in that market may be wrong. For connected devices, household products, and premium consumer categories, this usually shows up in subtle ways before it becomes obvious in revenue.
Gross margin integrity
Brands expanding internationally often discover that sales can rise while commercial quality falls.
Marketplace fees, promotional dependence, compliance costs, returns leakage, and fragmented repricing can dilute margin without immediately affecting volume. A benchmark that ignores margin integrity is incomplete because it rewards activity while hiding structural weakness.
What stronger brands do differently
The better operators don't use these pillars as isolated dashboards. They use them as an interconnected system.
If sales velocity drops while fulfilment reliability also slips, the commercial issue may not be demand. If review sentiment weakens while returns climb, the issue may be localisation. If revenue rises while margin integrity deteriorates, the ecosystem may be scaling in the wrong shape.
That's what makes performance benchmarking useful during expansion. It moves the conversation from “How are we doing?” to “What is this market telling us about the way our model is landing?”
A Step-by-Step Methodology for Brand Scaling
A benchmarking system only becomes commercially useful when it guides decisions. That requires a method, not just a dashboard.
Founders and commercial directors usually don't need more metrics. They need a way to decide what those metrics mean in a new region, and what to change next. The strongest methodology starts with the strategic question, then builds the comparison around that question.

Step one and step two
Frame the strategic question
Weak benchmarking starts with, “What are our numbers in Germany?”
Useful benchmarking starts with questions such as:
- Can this market support our premium positioning
- Is our current fulfilment model limiting conversion confidence
- Are we seeing a localisation issue or a demand issue
- Does this marketplace structure support brand control
That shift matters because it changes what you measure. If the question is strategic, the benchmark becomes diagnostic. If the question is too generic, the benchmark becomes descriptive and often unhelpful.
Define the comparison context
Many teams fail here, even when their data is clean.
Your peer set should reflect meaningful similarities, not broad category membership. Compare against brands with comparable price architecture, fulfilment expectations, service complexity, and market maturity. A premium hardware brand entering a new region should not benchmark itself against the full category average if much of that category competes on a very different operational model.
The benchmark should resemble your commercial reality, not your product taxonomy.
Step three and step four
Consolidate and normalise the data
Physical-product brands often pull disconnected signals from warehouse reports, carrier data, marketplace dashboards, reseller updates, and finance systems. On their own, those signals only tell partial stories.
For Australian operations with physical assets such as fleets or warehouses, benchmarking becomes more actionable when it uses a composite benchmark drawn from multiple data sources. Geotab highlights the value of combining sources such as telematics, weigh scales, and temperature sensors to identify inefficiencies like engine idling or underutilised assets, particularly across long transport distances and variable conditions, as outlined in this discussion of composite operational benchmarking.
The practical lesson goes beyond transport. In brand expansion, one KPI rarely explains enough. Composite views usually outperform isolated metrics because they connect cause and effect.
Identify performance gaps and ecosystem friction
This step is about interpreting mismatch.
If the product is converting but repeat purchase is weak, perhaps the offer attracts trial without building confidence. If traffic is healthy but margin is thinning, the issue may be channel leakage or fee drag. If customer sentiment varies by region, perhaps the localisation layer is inconsistent. The point is to locate where the operating model is rubbing against local market conditions.
Step five
Calibrate the go-to-market model
Once the friction is visible, the brand can adjust the model rather than react emotionally to the headline number.
That may mean tightening seller control, changing stock depth, refining local content, rethinking bundle architecture, revising pricing ladders, or altering fulfilment pathways. The best benchmarking process leads to fewer dramatic decisions and more precise ones.
A simple working sequence looks like this:
Ask a strategic question
Make the benchmark serve a decision, not a report.Build the right peer group
Similarity in operating model matters more than broad category labels.Normalise inputs across systems
Inconsistent definitions create fake gaps.Trace friction to a structural cause
Don't stop at the symptom.Adjust the market model and repeat
Performance benchmarking works best as an ongoing calibration cycle.
That repeatability is what separates growth from drift. International expansion rarely fails because brands lack data. It fails because they compare the wrong things, then act too quickly on the wrong conclusion.
From Data to Decision How to Interpret Benchmarking Signals
Collecting benchmarks is the easier part. Reading them properly is where commercial judgement shows up.
One pattern we continue seeing is that brands treat positive movement in one metric as proof that the whole ecosystem is healthy. That's rarely true. In practice, the most important signals come from combinations. Velocity plus rising returns. Revenue plus deteriorating margin. Review growth plus localisation complaints. Those pairings tell you far more than an isolated KPI ever will.
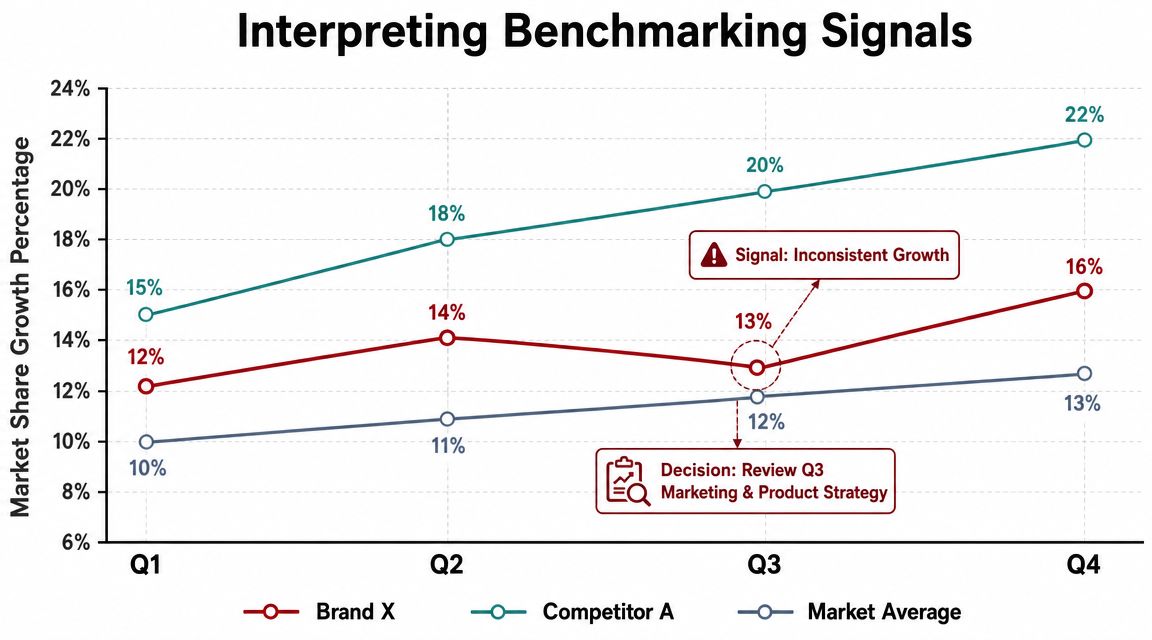
How experienced teams read mixed signals
A commercially mature reading of benchmark data usually looks like pattern recognition, not scorekeeping.
Consider a few common combinations:
| Signal pattern | Likely interpretation |
|---|---|
| Strong sales velocity with weak review quality | Demand exists, but expectation-setting may be poor |
| Rising revenue with declining gross margin | The market is growing in a less profitable shape |
| Healthy traffic with soft conversion | Pricing, trust, fulfilment, or localisation may be misaligned |
| Good first-order performance with weak repeat behaviour | Trial is happening, but brand fit or usage clarity is incomplete |
This is often where catalogue fragmentation becomes visible as a margin problem rather than just a brand-control problem. If pricing varies too widely, if duplicated listings create confusion, or if promotions are doing too much of the work, top-line growth can conceal structural leakage. That dynamic shows up clearly in many marketplace environments and is closely tied to the issues discussed in this piece on why Amazon margins shrink for brands with structural friction.
Average is often the wrong reference point
Another underserved angle in performance benchmarking is the difference between benchmarking against a peer average and benchmarking against the frontier.
Research on hospital performance found that improvement is better explained by movement in competitive distance to the benchmark frontier than by comparison with a static average, as discussed in this study on distance-to-frontier performance improvement. For expanding brands, the practical equivalent is this: the useful question isn't “Are we average for this category?” It's “Are we moving closer to the best feasible performance for our operating model in this market?”
That is a very different lens.
A premium brand with controlled distribution and stronger service expectations should not always benchmark itself against the broadest category average, because the category may include operators pursuing a completely different game. The frontier benchmark asks what excellent execution looks like for your type of brand, under your type of model, in that specific market.
Decision lens: Track trajectory toward the best feasible model, not just distance from the average.
Signals that deserve a second look
Not every red flag means retreat. Not every green flag means scale.
Founders should look harder when they see:
Fast early demand with unstable operational metrics
This can indicate curiosity without sustainable fit.Improving conversion with flat catalogue breadth
The market may accept the hero SKU while resisting the wider brand story.Margin pressure appearing before volume maturity
This usually points to structural inefficiency, not temporary launch noise.Regional inconsistency inside the same country group
Differences in fulfilment promise or channel execution may be driving uneven outcomes.
The best interpreters of benchmark data don't ask only what is changing. They ask why that change is happening, and whether it reflects market acceptance, ecosystem friction, or a model that hasn't been calibrated yet.
Building a Commercially Cohesive Global Presence
Performance benchmarking becomes powerful when it stops being a ranking exercise and starts becoming a way to build coherence across markets.
That's the primary challenge in international expansion. A brand doesn't merely add a new marketplace and continue as before. It moves into a different commercial environment with different expectations around delivery, localisation, trust, channel structure, and margin behaviour. The operating model has to travel well, not just the product.
Brands that scale cleanly across regions usually share one discipline. They don't compare dissimilar contexts as if they were interchangeable. They benchmark with context, they interpret with caution, and they adjust with intent. That creates something more valuable than a good launch report. It creates predictability.
One issue we repeatedly observe is that fragmented ecosystems damage performance before the business names the problem properly. Listings don't align. Fulfilment promises vary. Local language nuance is missed. Seller structure drifts. The brand appears present, but it doesn't feel cohesive to the customer. That's why marketplace expansion is never just a listing exercise. It's an ecosystem transition.
Localisation sits at the centre of that cohesion. A product that feels native to one market can feel slightly off in another for reasons that don't appear in a simple KPI report. Packaging cues, claims hierarchy, content tone, delivery expectations, and channel trust all shape how the offer is interpreted. That's why marketplace localisation changes how close a product feels to the buyer long before a spreadsheet explains the outcome.
The strongest global brands aren't always the ones posting the loudest single-market numbers. They're the ones that can scale with control, protect margin, preserve trust, and read market signals accurately as they move.
TPR Brands works with established product companies that need more than marketplace activity. It helps brands build commercially coherent expansion across regions, channels, and operating models, with practical support shaped by real marketplace behaviour, localisation demands, and fulfilment realities. If you're assessing international growth and want a more disciplined view of how your brand should benchmark, scale, and adapt, start the conversation with TPR Brands.